|
Denis Rozumny Note: my name can also be spelled Denys Rozumnyi. I am a Research Scientist at Meta Reality Labs. My main research interests include dynamic scene reconstruction, generative models, and photorealistic rendering. I finished my PhD at the Computer Vision and Geometry Group, Department of Computer Science, ETH Zürich under supervision of Prof. Marc Pollefeys. I also worked closely with Prof. Martin Oswald, Prof. Vittorio Ferrari, and Prof. Jiri Matas. Previously, I was a research intern at Google Research with Prof. Vittorio Ferrari and at Meta Reality Labs. Before that, I finished my MSc and BSc degrees from CTU in Prague, Center for Machine Perception under supervision of Prof. Jiri Matas. My research interests are in 3D reconstruction of objects and scenes, video understanding, realistic rendering, object detection, tracking, 6D pose estimation. In particular, I focus on test-time optimization methods to solve those problems. |

|
News
|
Research
|

|
BulletGen: Improving 4D Reconstruction with Bullet-Time Generation
Denys Rozumnyi, Jonathon Luiten, Numair Khan, Johannes Schönberger, Peter Kontschieder arxiv, 2025 arxiv \ paper We introduce an approach that takes advantage of generative models to correct errors and complete missing information in a Gaussian-based dynamic scene representation. |

|
A Recipe for Generating 3D Worlds From a Single Image
Katja Schwarz, Denys Rozumnyi, Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder ICCV, 2025 website \ arxiv \ paper We introduce a recipe for generating immersive 3D worlds from a single image by framing the task as an in-context learning problem for 2D inpainting models. |
|
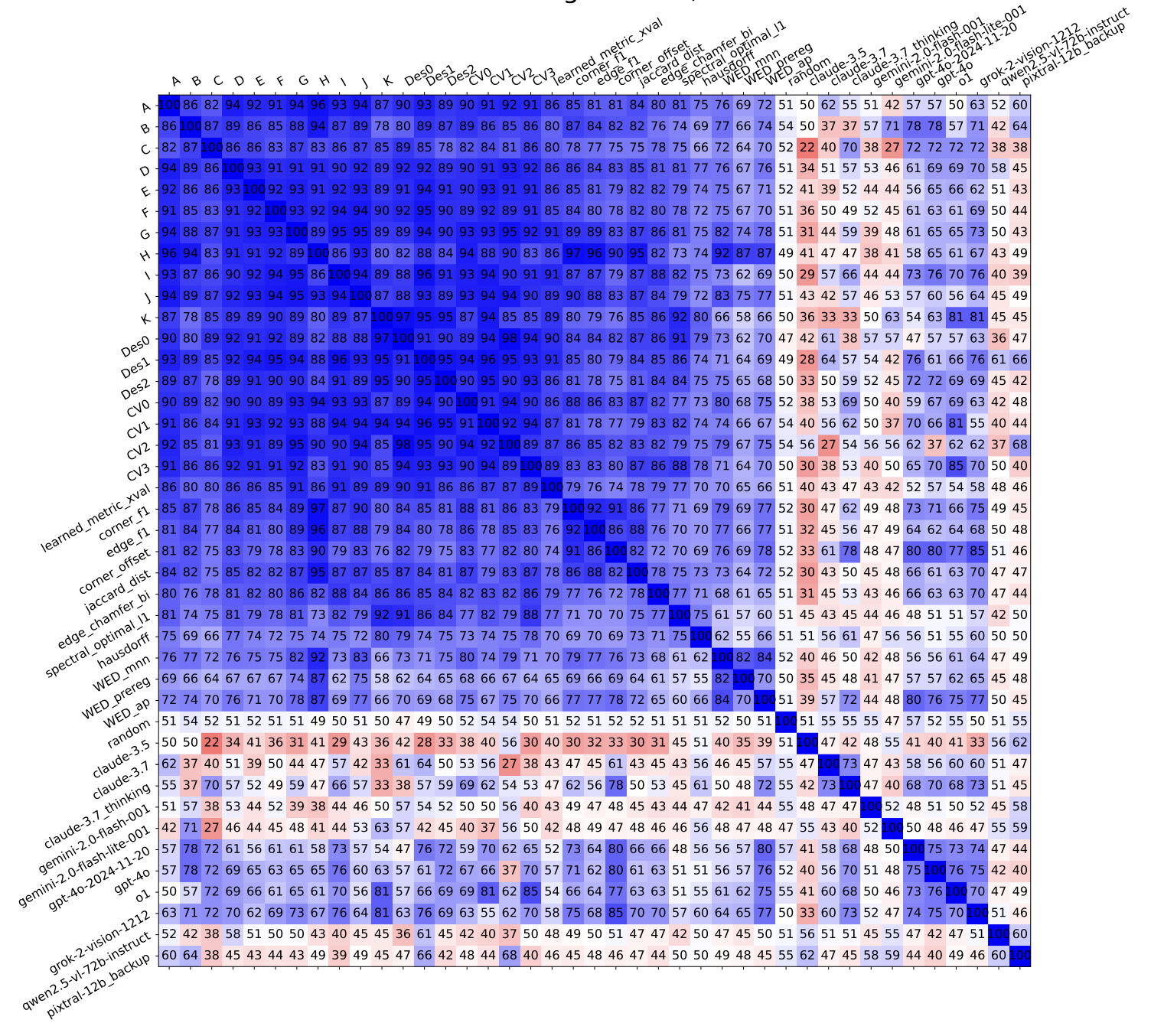
Explaining Human Preferences via Metrics for Structured 3D Reconstruction
Jack Langerman, Denys Rozumnyi, Yuzhong Huang, Dmytro Mishkin ICCV, 2025 arxiv \ paper We asked 3D modelers to rank wireframe reconstructions and compared it to the ranking by metrics. After I exploited issues in CVPR'24 challenge S23DR and won the 1st place, we came up with a better solution for the next challenge. |
|
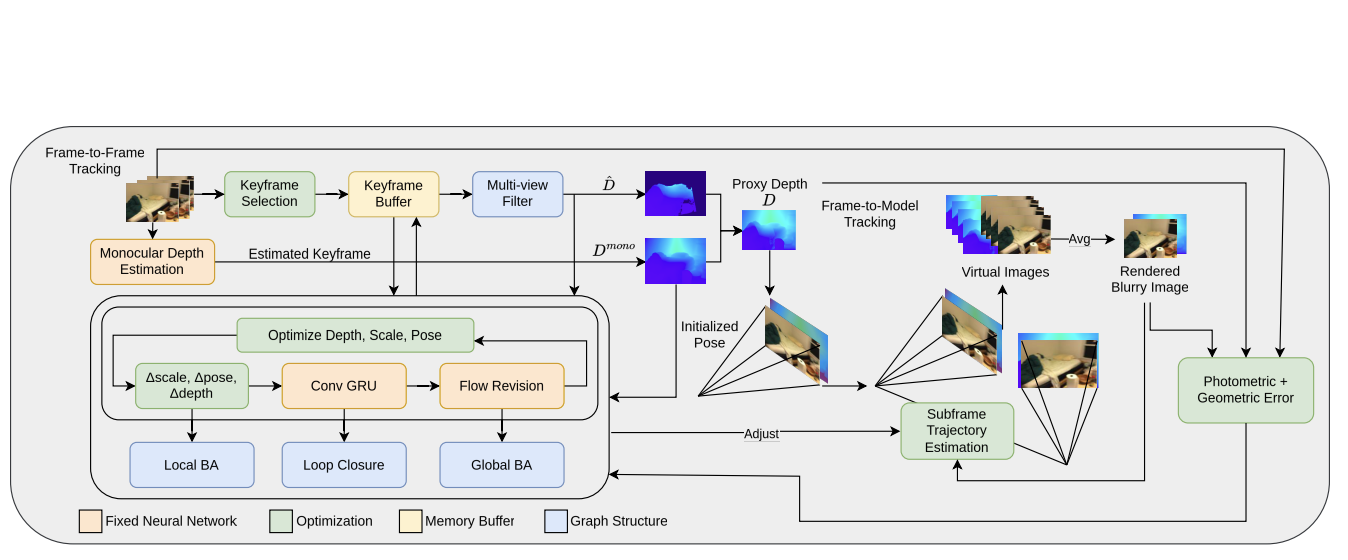
Deblur Gaussian Splatting SLAM
Francesco Girlanda, Denys Rozumnyi, Marc Pollefeys, Martin R. Oswald arxiv, 2025 arxiv \ paper Deblur-SLAM can successfully track the camera and reconstruct sharp maps for highly motion-blurred sequences. We directly model motion blur, which enables us to achieve high-quality reconstructions, both on challenging synthetic and real data. |

|
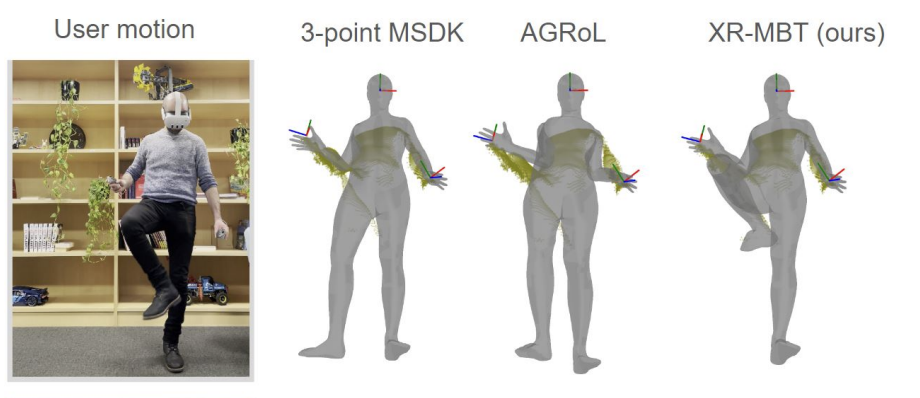
XR-MBT: Multi-modal Full Body Tracking for XR through Self-Supervision with Learned Depth Point Cloud Registration
Denys Rozumnyi, Nadine Bertsch, Othman Sbai, Filippo Arcadu, Yuhua Chen, Artsiom Sanakoyeu, Manoj Kumar, Catherine Herold, Robin Kips WACV, 2025 paper / arxiv We leverage the available depth sensing signal on XR devices combined with self-supervision to learn a multi-modal pose estimation model capable of tracking full body motions in real time. |

|
Retrieval Robust to Object Motion Blur
Rong Zou, Marc Pollefeys, Denys Rozumnyi, ECCV, 2024 paper / GitHub We propose a method for object retrieval in images that are affected by motion blur. |

|
Single-Image Deblurring, Trajectory and Shape Recovery of Fast Moving Objects With Denoising Diffusion Probabilistic Models
Radim Spetlik, Denys Rozumnyi, Jiri Matas, WACV, 2024 paper / GitHub A diffusion-based model that deblurs and recovers shape of fast moving objects from a single image without a known background (for the first time). |

|
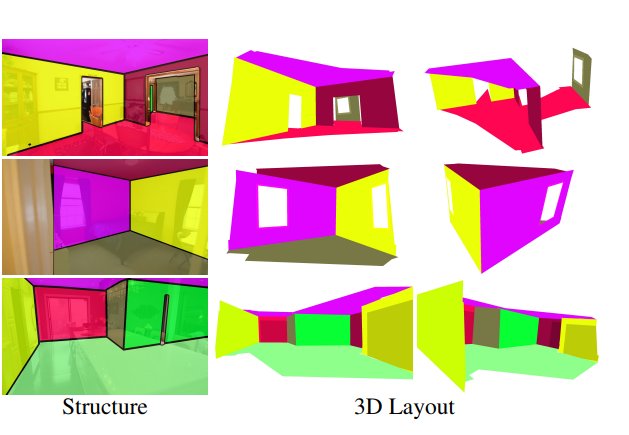
Estimating Generic 3D Room Structures from 2D Annotations
Denys Rozumnyi, Stefan Popov, Kevis-Kokitsi Maninis, Matthias Nießner, Vittorio Ferrari NeurIPS, 2023 arXiv / reviews / presentation / poster / poster source / GitHub We propose a novel method to produce generic 3D room layouts just from 2D segmentation masks, with which we annotate and publicly release 2246 3D room layouts on the RealEstate10k dataset. |


|
Human from Blur: Human Pose Tracking from Blurry Images
Yiming Zhao, Denys Rozumnyi, Jie Song, Otmar Hilliges, Marc Pollefeys, Martin R. Oswald ICCV, 2023 project page / arXiv / video / poster We estimate 3D human poses from substantially blurred images, e.g. extension of Shape from Blur to SMPL human body model. |

|
Tracking by 3D Model Estimation of Unknown Objects in Videos
Denys Rozumnyi, Jiri Matas, Marc Pollefeys, Vittorio Ferrari, Martin R. Oswald ICCV, 2023 arXiv / video / poster / poster source / GitHub We propose to guide and improve 2D tracking with an explicit object representation, namely the textured 3D shape and 6DoF pose in each video frame. |

|
Finding Geometric Models by Clustering in the Consensus Space
Daniel Barath, Denys Rozumnyi, Ivan Eichhardt, Levente Hajder, Jiri Matas CVPR, 2023 arXiv / GitHub A new algorithm for finding an unknown number of geometric models. |


|
Motion-from-Blur: 3D Shape and Motion Estimation of Motion-blurred Objects in Videos
Denys Rozumnyi, Martin R. Oswald, Vittorio Ferrari, Marc Pollefeys CVPR, 2022 arXiv / video / poster / poster source / GitHub Extension of Shape from Blur to multiple frames with more complex trajectories and exposure time modeling. |


|
Shape from Blur: Recovering Textured 3D Shape and Motion of Fast Moving Objects
Denys Rozumnyi, Martin R. Oswald, Vittorio Ferrari, Marc Pollefeys NeurIPS, 2021 arXiv / reviews / presentation / video / poster / poster source (keynote) / GitHub (110 stars) The first method to estimate textured 3D shape and sub-frame 6D motion of fast moving objects from a single frame. |

|
FMODetect: Robust Detection of Fast Moving Objects
Denys Rozumnyi, Jiri Matas, Filip Sroubek, Marc Pollefeys, Martin R. Oswald ICCV, 2021 arXiv / slides / poster / poster source / GitHub The first deep-learning based approach for fast moving object detection. |
|
DeFMO: Deblurring and Shape Recovery of Fast Moving Objects
Denys Rozumnyi, Martin R. Oswald, Vittorio Ferrari, Jiri Matas, Marc Pollefeys CVPR, 2021 project page / arXiv / video / poster / poster source / GitHub (165 stars) We propose DeFMO that given a single image with its estimated background outputs the object's appearance and position in a series of sub-frames as if captured by a high-speed camera (i.e. temporal super-resolution). This is the first deep-learning based approach for FMO deblurring. |
|

|
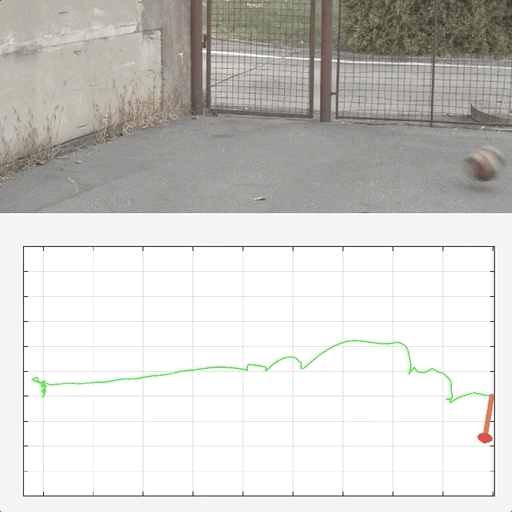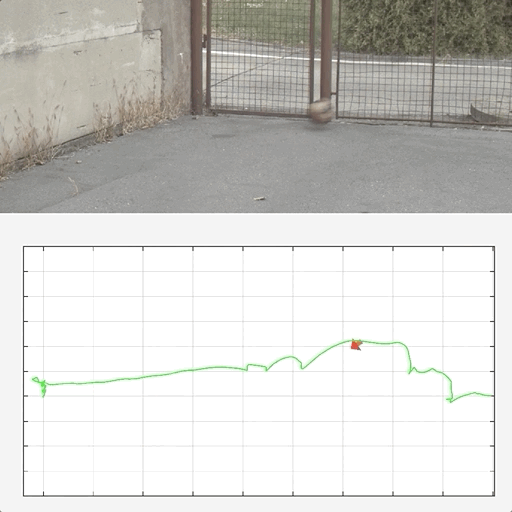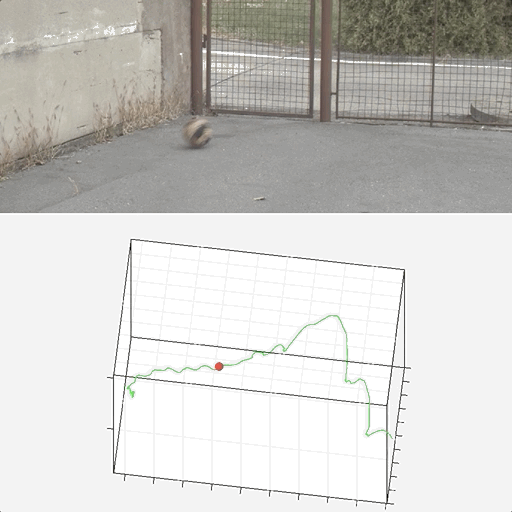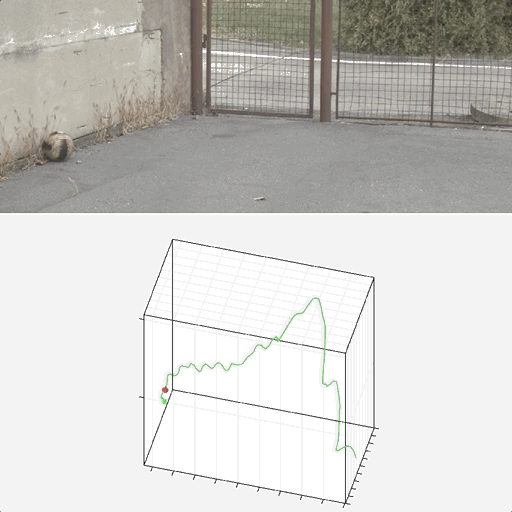
Tracking by Deblatting
Denys Rozumnyi, Jan Kotera, Filip Sroubek, Jiri Matas IJCV, 2021 project page / Springer / GitHub Summarization and extension of our GCPR'19 (TbD-NC) and ICCVW'19 (TbD) papers. |
|
Sub-frame Appearance and 6D Pose Estimation of Fast Moving Objects
Denys Rozumnyi, Jan Kotera, Filip Sroubek, Jiri Matas CVPR, 2020 project page / arXiv / video / GitHub We extend TbD pipeline to track fast moving objects in full 6 DoF, estimating simultaneously their 3D motion trajectory, 3D pose and object appearance changes with a time step that is a fraction of the video frame exposure time. |
|
|
Non-Causal Tracking by Deblatting
Denys Rozumnyi, Jan Kotera, Filip Sroubek, Jiri Matas GCPR, 2019 (Oral Presentation, Best Paper Honorable Mention) project page / arXiv / GitHub We apply post-processing with dynamic programming and curve fitting to obtain more accurate object trajectories. |

|
Intra-frame Object Tracking by Deblatting
Jan Kotera, Denys Rozumnyi, Filip Sroubek, Jiri Matas ICCVW, 2019 project page / arXiv / GitHub We propose a novel approach called Tracking by Deblatting to track fast moving objects. |

|
Learned Semantic Multi-Sensor Depth Map Fusion
Denys Rozumnyi, Ian Cherabier, Marc Pollefeys, Martin R. Oswald ICCVW, 2019 arXiv Our method learns sensor or algorithm properties jointly with semantic depth fusion and scene completion and can also be used as an expert system, eg to unify the strengths of various photometric stereo algorithms. |

|
The World of Fast Moving Objects
Denys Rozumnyi, Jan Kotera, Filip Sroubek, Lukas Novotny, Jiri Matas CVPR, 2017 project page / arXiv / poster / poster source Introducing fast moving objects for the first time as objects that move over distances larger than their size in one video frame: new problem, new dataset, new metrics, new baseline. |

|
Coplanar Repeats by Energy Minimization
James Pritts, Denys Rozumnyi, M. Pawan Kumar, Ondřej Chum BMVC, 2016 arXiv We propose an automated method to detect, group and rectify arbitrarily-arranged coplanar repeated elements via energy minimization. |

{kind=link}
Supervising
|
Reviewing
|
Teaching |
 |
Computer Vision: Teaching Assistant for Autumn Semester 2019, 2020.
Mixed Reality Lab: Teaching Assistant for Autumn Semester 2021. 3D Vision: Teaching Assistant for Spring Semester 2020, 2021, 2022. Deep Learning Seminar: Teaching Assistant for Spring Semester 2020 - 2024. |
|
Adapted from here. |